공정 데이터가 태어나는 곳들
📍 현재 위치: 데이터 한 점의 생애주기에서 하나의 데이터 점이 생애주기를 거치는 과정을 따라가 보았으니, 이제 공장 전체로 시야를 넓혀 — 단일클론항체(monoclonal antibody) 공정 전체를 공정 데이터가 태어나는 장소들의 사슬로서 다시 한번 걸어봅니다.
앞 장에서 우리는 센서나 분석자가 측정값을 만들어내는 순간부터 포착, 맥락화, 그리고 보관에 이르기까지 하나의 측정값을 추적했습니다 — 이것이 바로 이 책의 모든 내용을 떠받치는 척추인 데이터 생애주기(data lifecycle)입니다. 또한 우리는 메타데이터(metadata) — 어떤 값이 무엇을, 언제, 어디서, 어떤 조건에서 기록되었는지 말해주는 맥락 — 가 없는 원시 데이터(raw data)는 그저 잡음에 불과하다는 것을 배웠습니다. 이제 자연스럽게 다음 질문이 떠오릅니다. 그 모든 데이터 점들은 실제로 어디서 오는 것일까요? 그 답을 찾기 위해 우리는 바이오의약품 공장을 걸어서 둘러보되, 한 가지 비틀기를 더합니다. "각 기계가 무엇을 만드는가?"를 묻는 대신, "각 기계가 어떤 데이터를 내보내는가?"를 묻습니다.
바쁜 식당 주방을 둘러보는데, 음식은 볼 수 없고 주문표만 볼 수 있다고 상상해 보세요. 각 조리대 — 그릴, 튀김기, 플레이팅 작업대 — 는 저마다의 방식으로, 저마다의 리듬에 따라 자기만의 주문표를 토해냅니다. 바이오공정(bioprocess)도 마찬가지입니다. 모든 장비가 조용히 서로 다른 종류의 "주문표"를 찍어내고 있으며, 우리가 할 일은 공장을 액체의 흐름이 아니라 주문표의 흐름으로 읽어내는 것입니다.
이 장에서 다루는 내용
우리는 표준 공정도를 데이터 지도로, 조리대별로 — 상류(upstream) 세포 배양, 하류(downstream) 정제, 충전·마감(fill-finish), 그리고 품질관리(quality control) — 다시 그려볼 것입니다. 그 과정에서 이 책의 나머지 내용이 토대로 삼는 네 가지 개념을 소개합니다. 각 조리대가 특징적인 데이터 모양(shape) 을 내보낸다는 것, 공정 진행 중에 측정하는 것과 이후에 측정하는 것의 차이, 소프트 센서(soft sensor)가 이 둘을 어떻게 융합하는지, 그리고 모든 조리대의 데이터를 하나의 일관된 이야기로 엮어내는 배치 계보(batch genealogy)입니다. 마지막으로 연속 제조(continuous manufacturing)가 데이터의 모양 자체를 어떻게 바꾸는지 살펴보며 마무리합니다.
공정도는 곧 데이터 지도다
단일클론항체(monoclonal antibody, mAb) 는 살아있는 세포가 키워내는 치료용 단백질로 — 암과 자가면역 질환을 치료하는 데 쓰이는 종류의 의약품입니다. 이것을 만드는 일은 단위 조작(unit operation) 의 릴레이 경주입니다. 단위 조작이란 각각 전용 장비(바이오리액터, 크로마토그래피 컬럼, 필터)가 수행하는 개별적인 처리 단계를 말합니다. 이 공정을 그리는 전통적인 방식은 물질의 흐름으로 — 세포가 들어가고 정제된 약물이 나오는 것으로 — 표현하는 것입니다.
하지만 물질 다이어그램에는 결코 나타나지 않는, 또 하나의 평행한 흐름이 있습니다. 바로 데이터입니다. 현대 바이오공정의 기초 원리 — FDA의 공정 분석 기술(Process Analytical Technology, PAT) 프레임워크에서 규제기관이 공식화한 것으로, 이는 최종 제품만 시험하는 대신 공정이 진행되는 동안 측정함으로써 품질을 공정 안에 구축하도록 권장하는 지침입니다 [8] — 은 품질이 각 단계의 측정을 통해 이해되고 관리되어야 한다는 것입니다 [1]. 다시 말해, 모든 단위 조작은 동시에 데이터 스테이션(data station) 이기도 합니다. 각 단위 조작은 센서 판독값, 프로브 추적선(probe trace), 분석기 출력의 특징적인 서명을 생성하며, 이를 한데 모으면 그 안에서 무슨 일이 일어났는지 묘사하게 됩니다 [2].
그 렌즈를 끼고 보면 공장이 다르게 보입니다. 다음은 똑같은 mAb 공정을 각 조리대가 내보내는 데이터로 그린 것입니다.
 각 조리대는 서로 다른 종류의 데이터를 내보냅니다. 제조 라인은 동시에 데이터를 생성하는 라인이기도 합니다.
저자가 AI의 도움을 받아 직접 제작한 그림입니다.
각 조리대는 서로 다른 종류의 데이터를 내보냅니다. 제조 라인은 동시에 데이터를 생성하는 라인이기도 합니다.
저자가 AI의 도움을 받아 직접 제작한 그림입니다.
 프로브가 장착된 벤치 규모 바이오리액터 — 연속적인 온도, pH, 용존 산소 추적선을 생성하는 상류 데이터 소스. 이것은 벤치/개발 규모의 용기이지만, 아래에서 설명할 훨씬 큰 생산 탱크와 동일한 계측 장비를 갖추고 있어 함께 보여줍니다.
벤치 규모 바이오리액터. 이미지: Jonas Schenk, 퍼블릭 도메인, Wikimedia Commons.
프로브가 장착된 벤치 규모 바이오리액터 — 연속적인 온도, pH, 용존 산소 추적선을 생성하는 상류 데이터 소스. 이것은 벤치/개발 규모의 용기이지만, 아래에서 설명할 훨씬 큰 생산 탱크와 동일한 계측 장비를 갖추고 있어 함께 보여줍니다.
벤치 규모 바이오리액터. 이미지: Jonas Schenk, 퍼블릭 도메인, Wikimedia Commons.
상류: 시계열의 분수인 바이오리액터
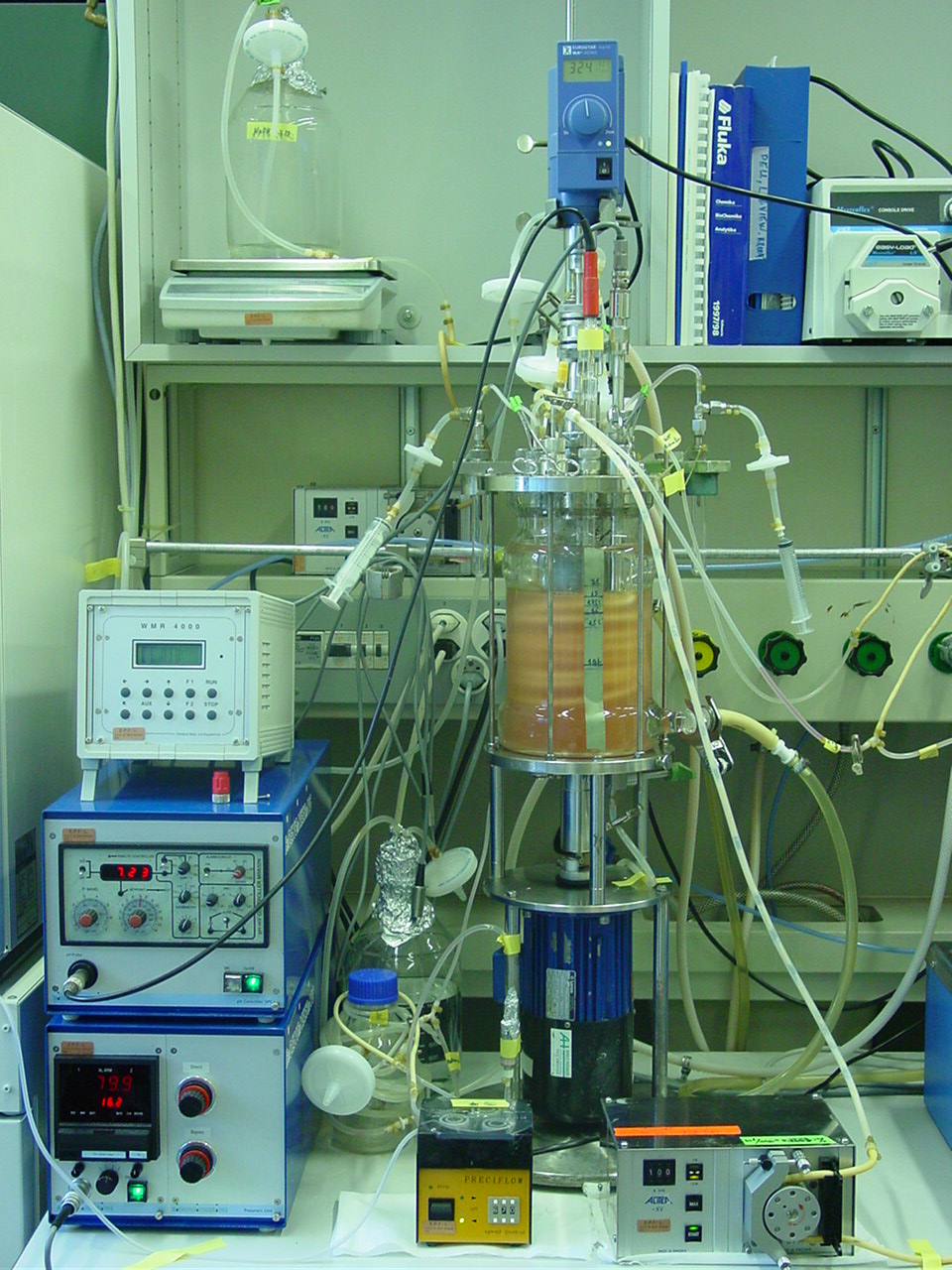
상류(upstream)란 세포 배양과 제품 생성을 의미합니다 — 세포를 키우는 일부터 수확(harvest), 즉 배양물이 세포로부터 분리될 준비가 된 시점까지의 모든 것입니다. (수확과 그 바로 다음의 청징 단계가 상류와 하류를 가르는 관례적인 경계입니다.) 상류의 중심에는 바이오리액터(bioreactor) 가 있습니다 — 세포가 살면서 제품을 분비하는, 계측 장비를 갖춘 큰 탱크로, 제조편의 생산 바이오리액터 장에서 물리적으로 다룹니다. 데이터 스테이션으로서 바이오리액터는 공장 전체에서 가장 시끄럽고 가장 연속적인 곳입니다.
각 스테이션의 데이터에는 모양이 있다: 스칼라, 분광, 이벤트
탱크 안의 프로브들은 몇 초마다 온도(temperature), pH(산성도), 용존 산소(dissolved oxygen)(세포가 호흡할 수 있는 산소)를 읽어내며, 조밀한 시계열(time-series) 데이터 — 측정된 시각이 찍힌 값들의 흐름 — 를 만들어냅니다. 전형적인 표본 하나는 히스토리언(historian)에 BR101.Temp.PV,2026-06-13T08:00:00Z,37.5,degC 와 같은 한 줄 — 하나의 태그, 하나의 타임스탬프, 하나의 값, 하나의 단위 — 으로 들어옵니다. 다만 바이오리액터가 지니는 태그가 이 세 개뿐인 것은 아닙니다. 생산용 용기는 온도, pH, DO, 교반(agitation), 여러 기체 유량, 헤드 압력(head pressure), 액위 또는 중량에 더해 그것들의 설정값과 몇몇 유도 태그(derived tag)까지 — 열 개가 넘는 채널을 — 보고하므로, 전체 태그 집합에 걸쳐 분당 수백 개의 줄이 도착합니다. 그 위에 개별 이벤트(discrete events) 가 겹쳐집니다. 각각의 영양분 피드, pH를 교정하기 위한 각각의 염기 투여량, 채취되는 각각의 시료가 그것입니다.
그리고 점점 더, 라만(Raman)과 같은 분광 프로브 — 배양액 안으로 빛을 쏘아 그 빛이 산란되는 방식으로부터 화학 조성을 추론하는 — 가 바이오리액터를 그 자체로 하나의 다변량(multivariate) 데이터 소스로 만듭니다. 하나의 인라인(in-line) 라만 프로브가 포도당, 젖산, 글루타민, 그리고 생존 세포 밀도(배양물의 두 가지 핵심 영양분, 주요 노폐물, 그리고 살아있는 세포의 수)를 실시간으로 동시에 추적할 수 있음이 입증된 바 있어 [4], 과거에는 네 번의 개별적인 실험실 채취(실험실로 보내지는 시료)였던 것이 하나의 연속적인 스트림이 됩니다. 라만 스캔 하나하나는 파수(wavenumber)에 대한 세기(intensity)의 온전한 스펙트럼 — 수백 개의 점 — 이며, 네 가지 분석물(analyte) 농도는 거기서 직접 읽히는 것이 아니라 다변량 보정(calibration) 모델(PLS)에 의해 예측됩니다. 이 모델은 배양물이 나이 들면서 표류할 수 있는 바로 그 종류의 모델입니다. 라만과 그 사촌격 기술들은 다음 장에서 제대로 소개합니다. 여기서는 바이오리액터 하나만으로도 수십 개의 상관된 채널을 한 번에 내보낼 수 있다는 것을 보는 것으로 충분합니다.
더 깊은 핵심은, 바이오리액터가 이미 세 가지 모양의 데이터를 뒤섞는다는 점입니다 — 조밀한 스칼라(scalar) 시계열(온도), 고차원 분광(spectral) 벡터(라만 스캔), 그리고 타임스탬프가 찍힌 이벤트(event)(피드). 단 하나의 모양만 내보내는 스테이션은 없고, 세 가지를 모두 담는 단 하나의 저장소도 없습니다. 각 신호의 모양을 알아보는 것이 데이터 아키텍처가 내리는 첫 번째 설계 결정인데, 모양이 저장·압축·질의 방식을 모두 좌우하기 때문입니다. 이를 아래의 하나의 기록 형식, 여러 모양 절에서 구체화합니다.
인라인, 온라인, 앳라인, 오프라인: 네 가지 위치와 그 지연
이는 우리의 첫 번째 큰 구분을 도입합니다. 모든 측정이 공정 흐름에 대해 같은 위치에서 이루어지는 것은 아닙니다. 측정은 센서가 공정 흐름 안에 자리 잡고 시료를 빼내지 않은 채 그 자리에서 읽어낼 때 인라인(in-line) 입니다 — 배양액에 잠긴 온도 프로브가 인라인이며, 결과는 연속적으로 도착합니다. 대신 기술자가 시료를 뽑아 가까이서 곧바로 읽을 때 그 측정은 앳라인(at-line) 입니다. 그리고 인라인과 앳라인 사이에 자리 잡은 세 번째 위치, 온라인(on-line) 이 있습니다 — 작은 부분 흐름(side-stream)이 공정에서 자동으로 분기되어 나와 측정되고, 종종 되돌아갑니다 — 바로 이 때문에 "온라인" 데이터는 "인라인" 데이터와 완전히 같지는 않습니다. 이 세 가지 — 인라인, 온라인, 앳라인 — 가 FDA의 PAT 프레임워크가 정의하는 공정 분석기(process-analyzer) 모드입니다 [8]. 이에 대비되는 것이 오프라인(off-line) 측정 — 시료를 가져가 나중에 별도의 실험실에서 분석하는 것 — 으로, 이는 측정을 공정에 더 가까이 옮김으로써 PAT가 줄이고자 하는 관례적인 방식입니다. 다음 장인 기기와 센서에서 이 네 가지 위치를 모두 상세히 나누어 다룹니다. 지금은 한 가지만 기억하세요. 바이오리액터는 홍수처럼 쏟아지는 연속적인 인라인(그리고 일부 온라인) 데이터를, 나중에 반드시 다시 결합되어야 하는 가느다란 앳라인 및 오프라인 실험실 결과의 물줄기와 뒤섞습니다.
네 가지 위치는 단순한 어휘가 아니라 하나의 가혹한 절충을 묘사합니다. 왼쪽에서 오른쪽으로 — 인라인에서 오프라인으로 — 옮겨갈수록 지연(latency)은 커지고 빈도(frequency)는 낮아지지만, 결정성(definitiveness) 은 높아집니다. 인라인 프로브는 빠른 간접 대리 지표를 주는 반면, 오프라인 HPLC(고성능 액체 크로마토그래피, high-performance liquid chromatography)는 실제로 배치를 출하하는(사용 승인을 내리는 공식적인 결정) 느린 기준 등급의 숫자를 줍니다.
 네 가지 측정 위치는 지연과 빈도를 결정성과 맞바꿉니다. PAT는 측정을 공정 쪽 왼쪽으로 옮깁니다.
저자가 AI의 도움을 받아 직접 제작한 그림입니다.
네 가지 측정 위치는 지연과 빈도를 결정성과 맞바꿉니다. PAT는 측정을 공정 쪽 왼쪽으로 옮깁니다.
저자가 AI의 도움을 받아 직접 제작한 그림입니다.
시계열 밀도와 조정: 연속과 희소를 융합하기
홍수와 물줄기를 다시 결합하는 일 자체가 하나의 데이터 문제이며, 바로 이 지점에서 소프트 센서(soft sensor) 가 제값을 합니다. 소프트 센서는 빈번한 온라인 신호와 드문드문한 앳라인 또는 오프라인 값을 융합하여, 어떤 단일 프로브도 직접 측정하지 못하는 공정 변수 — 바이오매스, 성장률, 또는 포도당 흡수율 — 를 직접 측정하는 대신 모니터링과 제어를 위해 실시간으로 추정하는 모델입니다 [6]. 예를 들어, 어떤 소프트 센서는 빈번한 라만 스펙트럼 판독값을 가끔씩의 수동 세포 계수(manual cell count)와 짝지어 실시간 바이오매스 농도를 추론함으로써, 분석자의 다음 실험실 결과가 몇 시간 뒤에야 도착하기 전에 제어 시스템이 피드를 조정할 수 있게 합니다. 온라인 흐름은 소프트 센서에 리듬을 주고, 가끔씩 들어오는 실험실 값은 그것이 정직함을 유지하게 합니다. 이것은 단순한 편의 이상입니다. 소프트 센서가 데이터 아키텍처의 심장부에 자리 잡는 이유가 바로 이것이며, 빠르지만 간접적인 신호와 느리지만 신뢰할 수 있는 신호를 제어기가 작동의 근거로 삼을 수 있는 하나의 숫자로 바꾸어내는 방식이 곧 소프트 센서이기 때문입니다.
이 조정은 서로 다른 속도로 째깍이는 두 시계보다 더 깊은 문제입니다. 인라인 스트림과 실험실 채취는 시간상 거의 들어맞지 않습니다 — 수동 세포 계수는 08:00에 채취되지만 11:00이 되어서야 결과가 돌아오며, 그 사이 바이오리액터는 이미 만 개가 넘는 판독값을 더 내보냈습니다 — 따라서 둘을 융합한다는 것은 한 번도 찍힌 적 없는 공정 시점에 값을 정렬(align) 하고, 둘이 어긋날 때 어느 신호를 믿을지 결정하는 것을 의미합니다. 그 정렬·신뢰 문제가 상류 데이터 관리의 살아있는 최전선이며, 이 장을 마무리하는 열린 과제의 핵심입니다.
하류: 청징, 추적선, 그리고 단계 이벤트
하류(downstream) 는 정제입니다 — 세포가 만들어낸 다른 모든 것으로부터 항체를 분리하는 일입니다. 하류는 청징 및 포집(clarification and capture) 으로 시작합니다. 수확된 배양액을 원심분리기와 심층 필터(depth filter)에 통과시켜 첫 번째 컬럼에 들어가기 전에 세포와 잔해를 제거하는 단계입니다. 이 정돈 단계조차도 데이터 스테이션입니다 — 탁도(turbidity)(흐름이 아직 얼마나 흐린지를 나타내는 척도), 필터 압력(pressure), 유량(flow) 판독값을 내보내며, 이곳에서 압력이 상승하는 것은 다른 어디에서나 그렇듯이 필터가 부하를 받고 있다는 신호입니다.
하지만 하류의 일꾼은 크로마토그래피(chromatography) 입니다. 단백질 혼합물을 수지(resin)로 채워진 컬럼에 통과시켜, 어떤 분자는 붙잡고 다른 분자는 흘려보내는 방식으로 — 제조편의 포집 크로마토그래피 장에서 다루는 물리적 단계입니다. 항체에서 이런 첫 단계는 단백질 A 포집(Protein A capture)입니다 — 항체를 그 Fc 줄기로 붙잡는 친화성 수지로, 그동안 숙주 세포 단백질과 DNA는 씻겨 지나갑니다 — 그리고 데이터를 그것이 속한 실제 단위 조작에 근거 짓는 일은 그만한 가치가 있습니다. 스테이션이 내보내는 숫자는 그것을 만들어낸 조작에 비추어야만 무언가를 의미하기 때문입니다. 이를 운전하는 스키드(skid) — Cytiva의 ÄKTA process 라인이나 Sartorius의 Resolute 같은 공정 규모 시스템 — 는 단순한 펌프와 밸브가 아닙니다. 데이터 스테이션으로서 크로마토그래피 스키드는 연속 추적선(continuous traces) 의 합창에 날카로운 단계 이벤트(phase events) 가 더해진 것입니다. 컬럼 출구의 검출기들이 280 nm에서의 UV 흡광도(UV absorbance)(얼마나 많은 단백질이 지나가는지에 대한 대리 지표 — 로딩 중에는 거의 0에 가깝게 머물다가 용출 정점에서는 2.5 흡광도 단위(absorbance units)를 넘어 치솟을 수 있습니다), 전도도(conductivity)(염 농도에 대한 대리 지표), 그리고 pH 를 연속적으로 기록합니다 [5]. 그 위에 명명된 단계들(phases) — 로드(load), 세척(wash), 용출(elute), 재생(regenerate)(혼합물을 수지에 로드하고, 불순물을 씻어내고, 붙잡힌 제품을 용출시킨 뒤, 재사용을 위해 컬럼을 재생/세정하는 것) — 이 겹쳐지며, 각각은 조건의 의도적인 변화를 표시하는 타임스탬프가 찍힌 이벤트입니다.
이 원시 추적선들 위에 올라타는, 그리고 그 자체가 계보가 실어 날라야 하는 데이터인 두 개의 유도된 숫자가 있습니다. 첫 번째는 돌파 어깨(breakthrough shoulder)입니다. 수지의 동적 결합 용량(dynamic binding capacity, DBC) — 운전 유량에서 수지 1리터가 붙잡는 항체의 그램 수로, 전형적으로 40에서 80 g/L — 를 넘겨 로드하면 결합하지 못한 제품이 바닥으로 빠져나가기 시작하며, 이는 로드 단계 UV 추적선의 조용한 상승으로 보입니다. 두 번째는 유출 단백질 A(leached Protein A) 추세입니다. 붙잡는 리간드의 일부가 주기마다 비드에서 조금씩 떨어져 나오므로, 배치별 ppm(parts-per-million) 결과는 수지가 검증된 주기 수명 한계를 향해 나이 들어감에 따라 올라갑니다. 어느 쪽도 단 한 순간에서 읽히지 않습니다. 둘 다 추적선을 가로질러, 그리고 수지의 재사용 이력을 가로질러 계산되며, 바로 이 때문에 크로마토그래피 기록은 타임스탬프뿐 아니라 컬럼 로트와 그 주기 수에 묶이지 않으면 불완전합니다. 결정적인 순간은 정제된 제품을 모으기 시작하고 멈추는 시점, 즉 풀링(pooling) 결정입니다. 작업자는 용출 정점에서 두 개의 컷 포인트(cut points) 사이의 조각만을 제품으로 모으며, 이는 컬럼 부피(column volume) 단위의 UV 임계값에 비추어 판단됩니다. 그 컷 포인트 선택은 실시간 품질 결정입니다 — 너무 늦게 잡으면 응집물이 많은 꼬리가 풀로 끌려 들어옵니다 — 따라서 이는 검토 가능하고 귀속 가능한 배치 기록의 일부로 기록되어야 하며, 이것이 바로 PIC/S PI 041 이 틀 짓는 크로마토그래피 데이터 무결성 기대입니다. 관례적으로 풀링 판단은 표준 UV 추적선으로 합니다. 더 진보된 접근법은 이를 직접 측정합니다 — 한 대규모 실증에서는 온라인 HPLC 분석기가 데이터 자체로부터 실시간 풀링 판단을 내렸으나 [5], 이는 일상적인 관행이라기보다는 실증된 기법으로 남아 있습니다. 세 번째 책이 오픈소스 하류 크로마토그래피 모듈을 구축할 때, 추적선의 합창에 단계 이벤트가 더해진 — 그리고 유도된 돌파, 풀링, 유출 리간드 결정이 더해진 — 바로 이 데이터가 그것이 포착하고 타임스탬프를 찍어야 하는 대상입니다.
 공정용 크로마토그래피 스키드. 각 정제 단계는 UV, 전도도, pH 추적선에 더해 개별적인 단계 전이 이벤트를 내보냅니다. (사진 속 장비는 초기의 Amersham Pharmacia Biotech 시스템이며, ÄKTA와 Resolute 라인은 현재의 예시로만 언급된 것입니다.)
이미지: Kitmondo Lab, CC BY 2.0(https://creativecommons.org/licenses/by/2.0/), Wikimedia Commons (File: Amersham Pharmacia Biotech chromotography skid.jpg).
공정용 크로마토그래피 스키드. 각 정제 단계는 UV, 전도도, pH 추적선에 더해 개별적인 단계 전이 이벤트를 내보냅니다. (사진 속 장비는 초기의 Amersham Pharmacia Biotech 시스템이며, ÄKTA와 Resolute 라인은 현재의 예시로만 언급된 것입니다.)
이미지: Kitmondo Lab, CC BY 2.0(https://creativecommons.org/licenses/by/2.0/), Wikimedia Commons (File: Amersham Pharmacia Biotech chromotography skid.jpg).
크로마토그래피 단계들 사이에 끼어 있는 것이 접선 흐름 여과(tangential flow filtration, TFF) 입니다 — 액체를 막을 가로질러 밀어내어 제품을 농축하거나 그 완충액을 교체하는 것입니다. 그 데이터 서명은 더 단순하지만 그만큼 의미심장합니다. 플럭스(flux)(액체가 막을 얼마나 빨리 가로지르는지)와 막간차압(transmembrane pressure)(액체를 막 너머로 밀어내는 압력 차이)입니다. 서서히 기어오르는 압력 상승은 막이 막혀가고 있음을 보고하는 막의 방식입니다.
이 패턴에 주목하세요. 각 조리대는 데이터의 모양을 가지고 있습니다. 바이오리액터의 것은 길고 조밀한 시계열이고, 크로마토그래피의 것은 이벤트로 구두점이 찍힌 추적선의 묶음이며, TFF의 것은 한 쌍의 압력·유량 신호입니다. 이 모양들을 알아보는 것이 데이터 관리의 절반입니다. 각 모양은 서로 다르게 저장되고 분석되기를 원하기 때문입니다. 이 스테이션 서명들은 1장에서 본 네 가지 데이터 계열(families of data)의 원재료입니다 — 바이오리액터와 크로마토그래피 추적선은 공정 데이터 계열을, QC 크로마토그램은 품질 계열을 채우며 — 모두 동일한 배치 식별자(아래에서 소개할 ISA-88 배치 모델에 키로 연결되기에 s88.batch로 적습니다)에 묶입니다.
충전·마감과 QC: 마지막 방울과 최종 판정
충전·마감(fill-finish) 은 벌크 약물이 환자가 받는 바이알이나 주사기가 되는 곳입니다. 그 데이터는 혼합물입니다. 모든 용기에 대한 충전 중량(fill-weight)(스칼라 측정값의 연속적인 흐름), 각 단위의 결함을 검사하는 머신 비전(machine-vision) 이미지, 그리고 환경 모니터링(environmental monitoring) — 방이 청결하게 유지되었음을 입증하는 입자 수와 미생물 시료가 그것입니다.
마지막으로 품질관리(quality control, QC) 가 옵니다 — 배치가 주장하는 그대로임을 확인하는 분석 실험실로, 제조편이 QC 및 출하에서 설명하는 단계입니다. QC는 오프라인(offline) 데이터의 원형입니다. HPLC 와 같은 기기들은 시료가 채취된 지 몇 시간 또는 며칠 후에 크로마토그램(chromatogram)(곡선)과 결과 표를 만들어내며, 이때 사용되는 방법은 ICH Q2(R2) — 국제의약품규제조화위원회(International Council for Harmonisation, ICH), 즉 주요 규제기관 전반에 걸쳐 의약품 품질 요구사항을 조화시키는 기구가 펴낸 지침으로, 이것은 분석 절차 검증에 관한 지침의 2023년 개정판이며 분석 절차 개발에 관한 새로운 ICH Q14와 짝을 이룹니다 — 에 제시된 기준에 맞추어 검증됩니다 [9]. 이것들은 직접적인 분석 측정값이며, 배치를 출하하는 규제 등급의 무게를 지닙니다 — 바로 이 때문에 이것들은 자신이 묘사하는 배치와 조리대로 모호함 없이 다시 연결되어야 합니다.
하나의 기록 형식, 여러 모양
위의 모든 스테이션은 같은 원자 단위 — 하나의 태그가 붙은 판독값 — 를 내보내며, 배치 계보, 조정, 규제 신뢰의 모든 구조물이 그 한 기록을 제대로 갖추는 데 달려 있습니다. 앞 장 데이터 한 점의 생애주기는 바이오리액터의 용존 산소 값 2026-01-05T00:00:00Z, BR101.DO.PV, 40.8224, %sat, 192, BATCH-2026-001 위에서 이 기록을 필드 단위로 — 여섯 개의 필드(tag, timestamp, value, unit, quality, batch_id) 각각이 헐벗은 숫자를 작은 신분증으로 바꾸는 의도적인 선택임을 — 이미 해부했습니다. 그 해부를 여기서 되풀이하지는 않습니다.
이번 둘러보기에서의 새로운 핵심은, 모든 스테이션이 정확히 이 여섯 필드 골격을 내보내면서도, 그것이 실어 나르는 데이터는 천차만별의 모양으로 온다는 점입니다. 골격은 불변이지만, value 칸에 담기는 몸체는 그렇지 않습니다.
- 바이오리액터는
value에 평범한 스칼라를 떨어뜨립니다 —40.8224 %sat, 줄당 하나의 부동소수점 — 그리고 태그당 몇 초마다 한 줄씩 내보냅니다. - 크로마토그래피 스키드는 UV 용출 추적선을 하나의 부동소수점에 담을 수 없습니다. 그 판독값은 단계 이벤트로 구두점이 찍힌, 동기화된 스칼라 스트림(UV, 전도도, pH)의 묶음이므로, 각 채널이 골격의 자기 사본을 타고 갑니다.
- QC 실험실은 온전한 크로마토그램(chromatogram) — 숫자가 아니라 곡선 — 을 만들어냅니다. 여섯 필드 골격은 결과를 식별하는 헤더(header) 가 되고, 그 적재물(payload)은 첨부된 배열(array)입니다.
- 라만(Raman) 스캔은 온전한 분광 벡터 — 파수당 수백 개의 세기 — 로, 어떤 단일
value칸도 담을 수 없습니다. 이는 바로 그 동일한 골격을 키로 삼아 배열로 저장됩니다.
그래서 온도는 편안하게 담는 value 필드가, 수백 점짜리 라만 스펙트럼이나 QC 크로마토그램에는 잘못된 집입니다 — 바로 이것이 스테이션 데이터가 서로 다른 모양을 갖는 이유이고, 하나의 저장소가 그 모두에 결코 들어맞지 않는 이유입니다. 두 필드가 다시 한번 눈여겨볼 만한데, 이 모든 모양을 가로질러 변하지 않고 따라다니며 공장 전체를 조인 가능하게 만드는 것이 바로 이 둘이기 때문입니다. quality — 고전적인 OPC 관례의 히스토리언 품질 바이트(quality byte)(OPC는 산업 자동화의 표준 데이터 교환 프로토콜입니다. 192 Good, 64 Uncertain, 0 Bad)로, 센서 자신의 자기 평가에서 곧장 읽어낸 것 — 과 batch_id — "어느 순간의 40.8224 %sat"을 "이 운전 중의 40.8224 %sat"으로 바꾸는 관계형 조인 키로, 다음에 조립할 배치 계보를 가리키는 것 — 입니다.
 하나의 기록 형식, 여러 모양: 모든 스테이션이 동일한 여섯 필드 골격을 재사용하지만,
하나의 기록 형식, 여러 모양: 모든 스테이션이 동일한 여섯 필드 골격을 재사용하지만, value 칸은 스테이션에 따라 스칼라, 추적선, 크로마토그램, 또는 분광 벡터를 담습니다.
저자가 AI의 도움을 받아 직접 제작한 그림입니다.
원시 출력에서 맥락화된 증거로: 신뢰를 얻는 메타데이터
골격의 교훈은, 값이 자신의 맥락을 지닐 때에만 신뢰를 얻는다는 것입니다. 헐벗은 40.8224 는 귀속 불가능하고, 단위가 없고, 날짜가 없습니다 — 바로 앞 장이 경고한 "잡음" 그 자체입니다. 그것을 태그, 타임스탬프, 단위, 품질, 배치 식별자로 감싸는 것이 세 번째 책이 맥락화(contextualization) 라 부르는 것이며, 바로 이 여섯 필드 줄이 오픈소스 구축물이 딛고 선 기초 기록인 것은 우연이 아닙니다. 제조편은 값을 내보내는 물리적 생산 바이오리액터를 설명하고, 이 장은 그것이 되는 데이터 기록을 보여주며, 세 번째 책의 히스토리언과 시계열 데이터베이스 장은 그것을 문자 그대로 여섯 열짜리 ts.sensor_reading 줄 — tag, value, unit, quality, batch_id, 그리고 타임스탬프 — 로 저장하며, 동일한 BR101.DO.PV, 40.8224, %sat, 192, BATCH-2026-001 예시 위에 구축됩니다. 그 원시 줄을 조인 가능하고 질의 가능한 증거로 바꾸는 일 — 그 주위에 장비, 단계, 레시피 맥락을 더하는 일 — 은 세 번째 책이 맥락화에서 떠맡는 작업입니다. 그 실은 하나의 연속된 선입니다. 물리적 산물, 그다음 데이터 기록, 그다음 구체적인 데이터베이스 줄.
이 여섯 필드는 또한 규제 당국의 데이터 무결성 기대 — ALCOA+ 라는 약어로 요약되는 것 — 에 거의 일대일로 대응합니다. 즉 기록은 귀속 가능(Attributable), 판독 가능(Legible), 동시 기록(Contemporaneous), 원본(Original), 정확(Accurate) 해야 하며, 거기에 "+" 확장(완전(complete), 일관(consistent), 영속(enduring), 가용(available))이 더해집니다. batch_id 와 시료를 채취한 작업자는 판독값을 귀속 가능하게 만들고, 측정 순간에 기록된 타임스탬프는 그것을 동시 기록되게 하며, 센서에서 곧장 읽어낸 quality 바이트는 그것을 다시 입력된 사본이 아니라 원본이게 합니다. 하지만 ALCOA+는 골격 혼자서 증명할 수 있는 것보다 더 많은 것을 요구합니다. 기록을 내보내는 시스템이 실제로 작동한다는 것, 그리고 누구도 사후에 값을 몰래 바꿀 수 없다는 것입니다. 그것이 전산화 시스템 검증(Computerized System Validation) 의 몫입니다 — GAMP 5 의 위험 기반 지침서와 IQ/OQ/PQ(설치 적격성 평가(Installation Qualification), 운영 적격성 평가(Operational Qualification), 성능 적격성 평가(Performance Qualification))의 단계들 아래에서, 히스토리언과 MES가 의도된 일을 하고 해서는 안 될 일은 하지 않음을 증명하는 것입니다 — 그리고 배치를 출하하는 전자 기록에 대해 21 CFR Part 11(미국)과 EU Annex 11(EU)이 의무화하는 감사 추적(audit trail) 의 몫입니다. 업계는 이 증명을 하는 방식을, 모든 것을 문서화하는 소진적인 CSV 에서 위험 기반 컴퓨터 소프트웨어 보증(Computer Software Assurance, CSA) — 검증 노력을 모든 필드에 균일하게가 아니라 환자 위험이 가장 높은 곳에 쏟는 것 — 으로 옮겨가고 있으며, CSV에서 CSA로 장이 그 이동을 온전히 짚어 갑니다. 이번 둘러보기를 위한 짧은 요약은 이렇습니다. 스테이션의 판독값은 그것을 기록한 검증된 시스템만큼만 신뢰할 수 있습니다 — 검증되지 않은 히스토리언 위의 여섯 필드 기록은 잘 정돈된 풍문입니다.
배치 계보: 조리대들을 하나의 이야기로 꿰매기
각 조리대는 참되지만 부분적인 이야기를 들려줍니다. 의약품은 배치(batch) — 정의된 하나의 제품 수량 — 이며, 이를 판단하려면 모든 조리대의 데이터를 하나의 추적 가능한 서사로 엮을 수 있어야 합니다. 어느 바이오리액터 운전이, 어느 배지 로트로 공급받았고, 어느 하류 컬럼들로 공급했으며, 어느 라인에서 충전되었고, 어느 QC 결과로 시험되었는지를 말입니다. 그 사슬이 배치 계보(batch genealogy)(또는 계통, lineage)입니다. 이것은 선택적인 기록 관리가 아닙니다. 완전한 배치 기록(batch record)은 미국에서 21 CFR Part 211 Subpart J 에 의해, 그리고 그것을 보관하는 전산화 시스템에 대해서는 EU Annex 11 에 의해 의무화되어 있으며(둘 다 1장에서 소개됨), 규제기관은 이 종단 간 추적성(traceability) 을 관리 전략 — 품질을 보증하는 문서화된 관리 계획 — 의 기둥으로 취급합니다 [7].
실제로 이 연결은 은유가 아닙니다. 그것은 모든 기록에 적히는 공유된 키(shared key)입니다. 동일한 배치 식별자 — 아래의 BATCH-2026-001 — 가 바이오리액터 스트림, 크로마토그래피 풀(pool), 그리고 QC 결과에 각인되므로, 그 하나의 값으로 질의하면 전체 이야기를 다시 짜맞출 수 있습니다.
{
"batch_id": "BATCH-2026-001",
"station": "BR101",
"timestamp": "2026-06-13T08:00:00Z",
"temperature_degC": 37.5,
"pH": 7.0,
"DO_pct_sat": 40.8,
"operator": "A. Okafor"
}
각 조리대의 기록은 — 배지와 피드 로트를 동반한 바이오리액터 운전, 크로마토그래피 풀링 결정, TFF 압력 및 플럭스 기록, 충전 중량과 비전 결과, QC 출하 데이터 — 모두 동일한 배치 식별자를 지니므로, 하나의 추적 가능한 트리로 엮입니다:
 데이터로 본 배치 계보(genealogy): 모든 단계가 동일한 배치 식별자(BATCH-2026-001)로 각인됩니다.
저자가 AI의 도움을 받아 직접 제작한 그림입니다.
데이터로 본 배치 계보(genealogy): 모든 단계가 동일한 배치 식별자(BATCH-2026-001)로 각인됩니다.
저자가 AI의 도움을 받아 직접 제작한 그림입니다.
관계형 접착제로서의 배치 계보: 모든 판독값에 태그 붙이기
실제 공장에서 이 연결은 전용 소프트웨어의 몫입니다 — 시계열을 포착하는 데이터 히스토리언(data historian) 과, 어느 로트, 어느 라인, 어느 작업자가 어느 배치에 속하는지를 기록하는 Korber Werum PAS-X, Rockwell FactoryTalk PharmaSuite, 또는 DELMIA Apriso 같은 제조 실행 시스템(manufacturing execution system, MES) 이 그것입니다. 그 기록들이 구조화되는 방식 자체도 표준화되어 있습니다. ISA-88 배치 제어 표준이 배치와 그 절차적 단계들이 어떻게 기술되는지를 정의하며 — 계보가 매달리는 s88.batch 기록의 이름을 짓는 것이 바로 이 표준입니다 — ISA-95 가 그 작업 현장 정보가 위쪽의 비즈니스 시스템과 어떻게 연결되는지를 규정합니다 — 자동화와 공장 아키텍처를 상세히 살펴볼 때 다시 돌아올 표준들입니다.
그 메커니즘은 판독값 골격에서 비롯한 바로 그 batch_id 필드입니다. 모든 단 하나의 줄 — 상류 바이오리액터 스트림, 크로마토그래피 풀, QC 표 — 이 그 동일한 키를 지니기 때문에, 계보는 유지해야 할 별도의 문서가 아니라 잘 태그된 판독값들의 창발적(emergent) 속성입니다. 태어날 때 키를 올바로 각인하면 트리는 질의만으로 스스로 조립됩니다. 이는 FAIR 원칙(FAIR principles, 찾을 수 있고 Findable, 접근 가능하고 Accessible, 상호운용 가능하며 Interoperable, 재사용 가능한 Reusable)의 축소판입니다. 잘 태그된 판독값은 키가 태어날 때 각인되었기에 바로 그 때문에 찾을 수 있고(Findable, batch_id로) 상호운용 가능합니다(Interoperable, 저장소를 가로질러 조인 가능). 세 번째 책은 이것을 문자 그대로 구현하여, 내보내는 모든 판독값이 이미 batch_id 를 지니는 오픈소스 상류 바이오리액터 수집 경로를 구축합니다. 그래서 배치를 재구성하는 관계형 조인은 조정 프로젝트가 아니라 평범한 SQL JOIN 입니다.
계보가 없으면 QC에서 발생한 일탈은 미아입니다 — 늦게 도착한 피드나 막힌 컬럼으로 거슬러 올라가 추적할 수 없습니다. 따라서 연결(linking) 은 데이터 관리의 핵심 행위이며, 바로 이것이 메타데이터가 중요한 이유입니다. 모든 데이터 점은 자신이 어느 배치와 어느 조리대에 속하는지 말해줄 충분한 맥락을 지녀야 합니다.
관계형 키에서 시맨틱 간선으로: 그래프로서의 계보
batch_id 조인 키는 계보의 관계형 형태입니다. 그런데 시맨틱 형태도 있으며, 이 둘을 함께 보는 것이 데이터가 어느 하나의 데이터베이스보다 오래 살아남게 해 줍니다. 네 번째 책 바이오의약품 제조를 위한 온톨로지는 같은 계보를 외래 키가 아니라 그래프 속의 방향 있는 간선(edge)으로 — 시맨틱 트리플(semantic triple)(주어-술어-목적어로 된 사실로, 그래프 데이터를 위한 W3C 표준인 RDF의 원자) 로 — 적습니다. "이 원료의약품은 이 배치로부터 만들어졌다"는 하나의 트리플 bp:derivedFrom 이 되며, 이는 전이적(transitive) 객체 속성으로 선언되어, 추론기는 직속 부모 간선만으로 세포 은행까지 거슬러 올라가는 사슬 전체를 추론합니다 — 누구도 그 장거리 링크를 단언할 필요가 없습니다.
# 각 스테이션의 기록을 계보 간선으로, 전이적으로 세포 은행까지 뿌리내린다.
bp:BATCH-2026-001 a bp:Batch ; bp:derivedFrom bp:SEED-001 .
bp:PApool-001 a bp:CapturePool ; bp:derivedFrom bp:BATCH-2026-001 . # the Protein A pool above
bp:DS-001 a bp:DrugSubstance ; bp:derivedFrom bp:PApool-001 .
이것은 외래 키가 살 수 없는 두 가지를 사 줍니다. 첫째, 정직하게 유형 지을 수 있는 출처(provenance) 입니다. 스테이션은 값을 산출하는 측정 이벤트를 내보내며, W3C 출처 온톨로지 PROV-O는 히스토리언의 quality 바이트와 타임스탬프를, 센서 prov:Activity 가 prov:wasGeneratedBy 한 prov:Entity 로 모델링하게 해 줍니다 — 이는 "배치"를 "그것을 만든 운전"과 구별되게 유지하는 바로 그 지속체 대 발생체의 구분(지속하는 것 대 일어났다가 끝나는 프로세스)과 같습니다. 둘째, 관계형 세계는 잊지 않고 실행해야만 하는 완전성 검사 입니다. SHACL 형상(Shapes Constraint Language, RDF의 닫힌 세계 검증기)은 출하된 로트에 필수 결과가 빠져 있을 때 지금 실패할 수 있는 반면, SQL은 조용히 널(null)이 든 행을 반환할 뿐입니다 — 그리고 검사관이 소리 내어 묻는 바로 그 적용 범위 질문이, 출하 게이트가 그렇게 하듯, 그래프가 답하는 한 줄짜리 SPARQL 역량 질문(competency question) 이 됩니다.
# Which drug products share the failed lot's lineage? (a recall scoped by query)
SELECT ?affected WHERE {
bp:DP-004 (bp:derivedFrom)+ ?shared . # walk up to a shared ancestor
?affected (bp:derivedFrom)+ ?shared . # then back down to its siblings
?affected a bp:DrugProduct . FILTER(?affected != bp:DP-004)
}
핵심은 한 형태가 옳고 다른 형태가 그르다는 것이 아니라 — 평범한 SQL JOIN 은 일꾼이고 그래프는 색인입니다 — 태어날 때 각인된 batch_id 가 둘 다를 가능하게 만드는 것이며, 시맨틱 형태는 스키마가 아니라 어휘를 공유하는 공장들을 가로질러 그 링크를 상호운용 가능하게 만드는 것입니다.
왜 중요한가
공장을 데이터 스테이션으로 재구성하는 것은 그 자체를 위한 은유가 아닙니다 — 그것은 데이터가 어떻게 다루어져야 하는지를 좌우합니다. 서로 다른 모양은 서로 다른 저장소를 요구합니다. 고빈도 시계열, 크로마토그래피 추적선의 묶음, 그리고 QC 결과 표는 각각 뚜렷이 다른 용량, 구조, 시점을 가집니다. 온라인 데이터와 오프라인 데이터는 엄청나게 다른 빈도(frequency)와 지연(latency)으로 도착하며 하나의 통합된 타임라인으로 조정되어야 합니다. 그리고 이 모든 것을 수집하는 본래의 목적 — 배치가 안전하고 효과적임을 입증하고 공정을 개선하는 것 — 은 모든 조리대의 출력이 하나의 계보로 연결되지 않으면 무너집니다. 데이터 아키텍처를 제대로 갖추면 공장은 읽힐 수 있게 되고, 잘못 갖추면 연결되지 않고 추적 불가능한 숫자 더미만 남게 됩니다.
열린 과제: 다중 속도 시계열의 조정
위의 모든 단정한 구조에도 불구하고, 이 데이터 흐름의 핵심에 자리 잡은 한 가지 문제는 여전히 진정으로 미해결입니다. 바이오리액터는 몇 초마다 고빈도 인라인 신호를 내보내지만, 앳라인 세포 계수와 오프라인 HPLC는 몇 분에서 몇 시간 뒤에, 그것도 드문드문 도착합니다. 두 속도를 하나의 신뢰할 수 있는 타임라인으로 융합하는 것이 바로 소프트 센서의 존재 이유입니다 — 하지만 소프트 센서는 공정에 적합화된 모델이며, 살아있는 세포 배양은 표류합니다. 세포는 나이 들고, 대사는 변하며, 운전 초기에 모델이 학습한 빠른 라만 신호와 느린 실험실 값 사이의 관계는 12일째에는 더 이상 그 관계가 아닙니다. 모델은 배치가 가장 값질 때 정확히 낡아버립니다.
어려운 부분은 소프트 센서를 만드는 것이 아니라 그 생애주기(lifecycle) 를 관리하는 것입니다. 모델이 조용히 제어기를 오도하기 전에 표류했음을 어떻게 감지할까요? 표류했다면 배치 도중에 재학습할까요 — 그렇다면 어떤 데이터로, 그리고 검증된 공정 안의 재학습된 모델은 재검증을 요구할까요? 바이오공정 소프트 센서에 관한 기초 현황 보고서는 바로 이 간극을 짚으며, 소프트 센서를 고정된 기기로 취급하는 대신 모델 유지보수, 표류 감지, 재학습에 체계적으로 주의를 기울일 것을 권고합니다 [6]. 10년이 넘게 지났지만, 표류 감지·재학습 루프에 대한 검증되고 규제기관이 인정한 표준은 여전히 없습니다 — 바로 이 때문에 가장 진보된 조정 기법들이 일상적이지 않고 실증된 채로 남아 있으며, 이것이 머신러닝과 소프트 센서 장이 깊이 다루며 떠맡는 열린 최전선 중 하나인 이유입니다.
세 가지 방법론적 요점이 그런 모델을 도대체 신뢰할 수 있는지를 결정하며, 데이터 아키텍처가 그 각각을 좌우합니다. 첫 번째는 모델을 어떻게 채점하는가 입니다. 소프트 센서의 정확도는 그것을 적합화한 데이터에서 읽어낼 수 없습니다 — 그 숫자는 자기 자신을 추켜세웁니다. 정직한 시험은 모델이 한 번도 보지 못한 데이터에 대한 점수이며, 바이오공정에서 유일하게 올바른 분할은 그룹화(배치 하나씩 빼기, leave-one-batch-out) 교차 검증 입니다. 즉 개별 판독값이 아니라 캠페인 전체를 빼두는 것입니다. 그 이유는 바로 이 장이 줄곧 그려온 스테이션 구조에 있습니다 — 바이오리액터 하나가 내보내는 수천 개의 상관된 시계열 행은 독립적인 관측이 아니므로, 그것들을 무작위로 분할하면 모델이 자기 답을 훔쳐보게 됩니다. 그 오염이 바로 데이터 누출(data leakage)(학습 정보가 시험 집합으로 새어 드는 것)이며, 누출된 점수는 아무것도 증명하지 못하는 검증입니다 — 바로 이 때문에 batch_id 필드는 단순한 조인 키가 아니라 모델이 그것으로 검증되어야 하는 단위입니다. 두 번째는 적용 가능 영역(applicability domain) 입니다. 소프트 센서는 학습된 조건의 봉투(envelope) 안에서만 유효하므로, 어떤 학습 배치와도 닮지 않은 스펙트럼이나 피드 상태는 자신만만하게 답하기보다 거부되어야 합니다 — 일회성 검사가 아니라 예측마다 작동하는 게이트입니다. 세 번째는 공정 표류(process drift) 와 모델 표류(model drift) 의 구별입니다. 살아있는 배양이 진정으로 움직이는 것(세포주 노화, 새 배지 로트) 대 모델의 정확도가 세상이 그 학습 데이터에서 멀어졌기에 떨어지는 것입니다. 이 둘은 서로 다른 기기에 잡힙니다 — 레이블 없는 입력 분포 모니터는 새 로트가 특징 분포를 옮기는 순간 발화하는 반면, 모델의 예측-실험실 잔차에 대한 관리도는 느린 오프라인 기준이 도착해야만 발화하는데 — 이는 위에서 본 바로 그 다중 속도 조정 문제를, 이번에는 모델 쪽에서 읽은 것입니다. 네 번째 책의 머신러닝 생애주기와 모델과 검증 장이 이 감지기들과 그것들을 둘러싼 잠금-후-재학습 거버넌스를 구축합니다. 여기서의 핵심은, 네 가지 모두 — 그룹화 교차 검증, 적용 가능 영역, 표류 감지, 그리고 변경 관리 하의 재검증 — 가 스테이션 태그가 붙고 배치 키가 매겨진 기록을 태어날 때 제대로 갖추는 데서 비롯하는 하류의 귀결이라는 점입니다.
현실 세계에서는
산업이 하나의 큰 탱크를 유가식(fed-batch) 모드 — 채우고, 한 번에 끝까지 운전한 뒤, 비우는 방식 — 로 운전하는 방식에서 통합 연속 바이오공정(integrated continuous bioprocessing) — 관류(perfusion) 바이오리액터(세포는 유지하면서 신선한 배지를 계속 공급하고 제품과 소모된 배지를 계속 빼내는 방식)가 최소한의 유지 부피로 정상 상태에서 운전되는 연속 하류 단계들로 공급하는 방식 [3] — 으로 옮겨감에 따라, 데이터 자체의 모양이 바뀝니다. 연속 운전은 단정하고 개별적인 배치를 정상 상태에서 연속적으로 모니터링되는 스트림(streams) 으로 대체하며 [3], FDA는 이를 배치 생산과 명시적으로 대조하면서 그것이 추적성과 관리 전략을 어떻게 재구성하는지 언급했습니다 [7]. 단일한 수확 이벤트가 없을 때 "배치"는 시간의 한 조각으로 정의되어야 합니다 — 그리고 연속 제조에 관한 2022년 지침인 ICH Q13 이 이제 바로 그것을 공식화하여, 연속 "배치"를 일정 기간에 걸친 투입량, 운전 시간, 또는 산출량으로 정의합니다 [10]. 이 변화는 실시간 통합과 파마 4.0에서 다시 다룹니다.
핵심 용어
- 단위 조작(unit operation) — 전용 장비가 수행하는 개별적인 처리 단계. 여기서는 데이터 스테이션이기도 합니다.
- 단일클론항체(monoclonal antibody, mAb) — 살아있는 세포가 키워내는 치료용 단백질.
- 공정 분석 기술(Process Analytical Technology, PAT) — 최종 제품만 시험하는 대신 공정이 진행되는 동안 측정함으로써 품질을 안에 구축하는 FDA 프레임워크.
- 수확(harvest) — 배양물이 세포로부터 분리될 준비가 된 시점. 관례적인 상류·하류 경계.
- 시계열 데이터(time-series data) — 기록된 시각이 각각 찍힌 값들의 흐름.
- 인라인(in-line) — 시료를 빼내지 않고 공정 흐름 안의 센서로 측정하여 연속적인 데이터를 주는 것.
- 온라인(on-line) — 부분 흐름이 공정에서 자동으로 분기되어 나와 측정되고 종종 되돌아가, 거의 연속적인 데이터를 주는 것.
- 앳라인 / 오프라인(at-line / off-line) — 빼낸 시료에 대해 측정하는 것으로, 가까이서 곧바로(앳라인) 또는 나중에 별도의 실험실에서(오프라인) 측정.
- 청징 및 포집(clarification and capture) — 정제 전에 수확된 배양액에서 세포와 잔해를 제거하는 것. 탁도, 압력, 유량을 내보냅니다.
- 크로마토그래피(chromatography) — 혼합물을 수지로 채워진 컬럼에 통과시켜 정제하는 것. UV, 전도도, pH 추적선을 내보냅니다.
- 풀링 결정(pooling decision) — 컬럼에서 정제된 제품을 모으기 시작하고 멈출 시점을 선택하는 것.
- 접선 흐름 여과(tangential flow filtration, TFF) — 막을 가로지르는 여과로 농축하거나 완충액을 교환하는 것. 플럭스와 막간차압을 내보냅니다.
- 충전·마감(fill-finish) — 벌크 약물을 바이알이나 주사기에 채우는 것. 충전 중량, 비전 이미지, 환경 데이터를 내보냅니다.
- 품질관리(quality control, QC) — 배치의 정체성과 품질을 확인하는 분석 실험실. 오프라인 데이터의 원형.
- 소프트 센서(soft sensor) — 온라인 신호와 드문드문한 앳라인 또는 오프라인 값을 융합하여, 어떤 프로브도 직접 측정하지 못하는 공정 변수를 추정하는 모델.
- 배치(batch) — 정의된 하나의 제품 수량.
- 배치 계보(batch genealogy, 계통) — 하나의 배치에 대해 모든 조리대의 데이터를 연결하는, 사슬로 엮인 추적 가능한 기록.
- 데이터 히스토리언(data historian) — 공장의 연속적인 센서 시계열을 포착하고 시각을 찍는 소프트웨어.
- 제조 실행 시스템(manufacturing execution system, MES) — 어느 로트, 어느 라인, 어느 작업자가 어느 배치에 속하는지를 기록하는 작업 현장 소프트웨어.
- 관리 전략(control strategy) — 제품 품질을 보증하는 문서화된 관리 계획.
- 유가식(fed-batch) — 하나의 탱크를 채우고, 한 번에 끝까지 운전한 뒤, 비우는 운전 방식. 연속 운전의 관례적인 대안.
- 통합 연속 바이오공정(integrated continuous bioprocessing) — 정상 상태에서 운전되는 연결된 단위 조작들로, 개별적인 배치가 아니라 데이터 스트림을 생성하는 것.
- 태그가 붙은 판독값(tagged reading) — 원자 단위 기록. 값에 태그, 타임스탬프, 단위, 품질 플래그, 배치 식별자가 더해진 것으로, 그 필드들이 정체성을 부여하기 전까지는 무의미함.
- 데이터 모양(data shape) — 스테이션 출력의 구조적 형태(스칼라, 분광, 크로마토그래피, 이벤트). 모양이 데이터가 저장되고 질의되는 방식을 좌우함.
- 소프트 센서 표류(soft-sensor drift) — 운전 중 공정이 변하면서 소프트 센서의 정확도가 점차 떨어지는 것. 검증된 표준이 아직 열려 있는 감지와 재학습을 요구함.
- 동적 결합 용량(dynamic binding capacity, DBC) — 운전 유량에서 포집 수지 1리터가 붙잡는 항체의 그램 수(전형적으로 40–80 g/L). 이를 넘겨 로드하면 UV 추적선에 돌파 어깨가 생김.
- 풀링 컷 포인트(pooling cut points) — 그 사이에서 용출 정점이 제품으로 모이는 두 개의 UV 임계값 표시(컬럼 부피 단위). 배치 기록 안의 실시간, 귀속 가능한 품질 결정.
- 시맨틱 트리플(semantic triple, RDF) — 주어-술어-목적어로 된 사실로, W3C 그래프 표준의 원자.
batch_id조인을 추론기가 전이적으로 걸을 수 있는derivedFrom계보 간선으로 바꿈. - 지속체 대 발생체(continuant vs. occurrent) — 지속하는 것(배치 물질)과 일어났다가 끝나는 프로세스(그것을 만든 운전) 사이의 상위 온톨로지 구분. "배치"를 "스테이션 이벤트"와 구별되게 유지함.
- 그룹화(배치 하나씩 빼기) 교차 검증(grouped (leave-one-batch-out) cross-validation) — 개별 판독값이 아니라 캠페인 전체를 빼두어 채점함으로써 상관된 배치 내부 행이 누출되지 못하게 하는 것. 스테이션 태그가 붙은 소프트 센서를 위한 유일하게 정직한 시험.
- 데이터 누출(data leakage) — 학습 정보가 시험 집합을 오염시키는 것(예: 한 배치의 상관된 행을 학습과 시험에 걸쳐 분할). 아무것도 증명하지 못하는 추켜세우는 점수를 낳음.
- 적용 가능 영역(applicability domain) — 모델이 학습된 조건의 봉투. 그 바깥의 입력은 자신만만하게 답하기보다 거부되어야 함.
- 공정 표류 대 모델 표류(process drift vs. model drift) — 살아있는 공정이 진정으로 움직이는 것 대 세상이 학습 데이터에서 멀어졌기에 모델의 정확도가 떨어지는 것. 서로 다른 감지기에 잡힘.
- ALCOA+ — 기록이 귀속 가능(Attributable), 판독 가능(Legible), 동시 기록(Contemporaneous), 원본(Original), 정확(Accurate)해야 하며, 거기에 완전(complete), 일관(consistent), 영속(enduring), 가용(available)이 더해진다는 데이터 무결성 기대.
- 컴퓨터 소프트웨어 보증(Computer Software Assurance, CSA) — 소진적인 CSV에 대한 FDA의 위험 기반 후계자. 검증 노력(GAMP 5, IQ/OQ/PQ, Part 11 / Annex 11 감사 추적)을 환자 위험이 가장 높은 곳에 쏟음.
이 다음은
우리는 공장을 데이터를 생성하는 조리대들의 사슬로 둘러보았고, 이 모든 데이터의 일차적 원천이 물리적 사물 — 프로브, 검출기, 카메라, 그리고 실험실 분석기 — 임을 보았습니다. 다음 장 데이터 소스로서의 기기와 센서는 그 기기들로 완전히 줌인합니다. 어디서 측정하는지(인라인, 온라인, 앳라인, 오프라인)에 따라 기기를 분류하고, 공정 분석 기술과 라만 및 NIR 같은 분광 센서를 제대로 소개하며, 각 기기가 어떻게 특징적인 데이터 모양 — 스칼라, 분광, 크로마토그래피, 또는 이미지 — 을 만들어내는지, 그리고 나머지 데이터 스택이 이를 받아들이도록 어떻게 구축되어야 하는지를 보여줍니다.